

{kind=link}
15Five es la plataforma estratégica de gestión del rendimiento que impulsa la acción y el impacto. Ayuda a los equipos de recursos humanos a tomar medidas estratégicas y transforma a los líderes en creadores de cambios. La plataforma completa de 15five, con impulsado de IA, incluye revisiones de rendimiento de 360 °, encuestas de participación, planificación de acción, seguimiento de objetivos, habilitación del gerente y herramientas de retroalimentación del administrador-empleado.
Thank you for reading this post, don't forget to subscribe!
Necesitamos sistemas de datos robustos que puedan procesar, analizar y superficies de superficie de millones de interacciones de los empleados para entregar estas capacidades a escala. Nuestro equipo de ingeniería creó una plataforma de datos sofisticada que alimenta estas características y permite la toma de decisiones estratégicas para los líderes de recursos humanos. Así es como lo hicimos.
Objetivos de la plataforma de datos de 15Five
El objetivo principal en la construcción de nuestra plataforma de datos period mejorar las capacidades de informes y análisis de 15Five, empoderando a los administradores de recursos humanos con información procesable sobre el rendimiento y el compromiso de los empleados. La plataforma utiliza datos históricos para permitir el análisis de tendencias, lo que brinda a los profesionales de recursos humanos una comprensión más clara de la dinámica de la fuerza laboral a lo largo del tiempo.
Más allá de los informes diarios, la plataforma nos permite realizar inteligencia empresarial avanzada y análisis predictivos utilizando modelos de aprendizaje automático y aprendizaje profundo. Estos modelos ayudan a los equipos de recursos humanos a predecir la facturación de los empleados e identificar los impulsores clave de la participación, lo que permite a las organizaciones tomar medidas proactivas para mejorar su entorno de trabajo.
Antes de implementar esta plataforma de datos, nuestros datos se dispersaron en múltiples sistemas, lo que dificulta la consolidación y analización. La nueva plataforma proporciona una solución unificada que alimenta nuestros resultados volantes y admite el desarrollo futuro de aplicaciones.
Los datos
La mayoría de nuestros datos se originan en las bases de datos de aplicaciones de 15Five, principalmente alimentadas por Amazon RDS Postgres y RDS Aurora (motor Postgres). En el núcleo se encuentra una gran instancia de Postgres que admite nuestra aplicación monolítica y una base de datos compartida utilizada por varios otros microservicios.
Estas bases de datos almacenan datos operativos clave esenciales para impulsar información en toda la plataforma. Nuestro procesamiento de datos centralizados permite informes y análisis cohesivos utilizando datos de todas las áreas del ecosistema de la aplicación.
La pila de tecnología
Dado que 15Five opera en gran medida en el ecosistema de AWS, period pure usar tecnologías AWS al construir la plataforma de datos. Este enfoque garantiza la escalabilidad, la seguridad y la consistencia en nuestra infraestructura.
Para nuestra solución de almacén de datos, elegimos AWS Redshift Servidor sin ser:
- Escala automáticamente calcula los recursos basados en la demanda
- Elimina la gestión de infraestructura guide
- Maneja eficientemente las cargas de trabajo fluctuantes
- Garantiza la disponibilidad de datos continuos para el análisis
- Previene el sobreprovisión de los recursos
Arquitectura de plataforma de datos: descripción normal de alto nivel
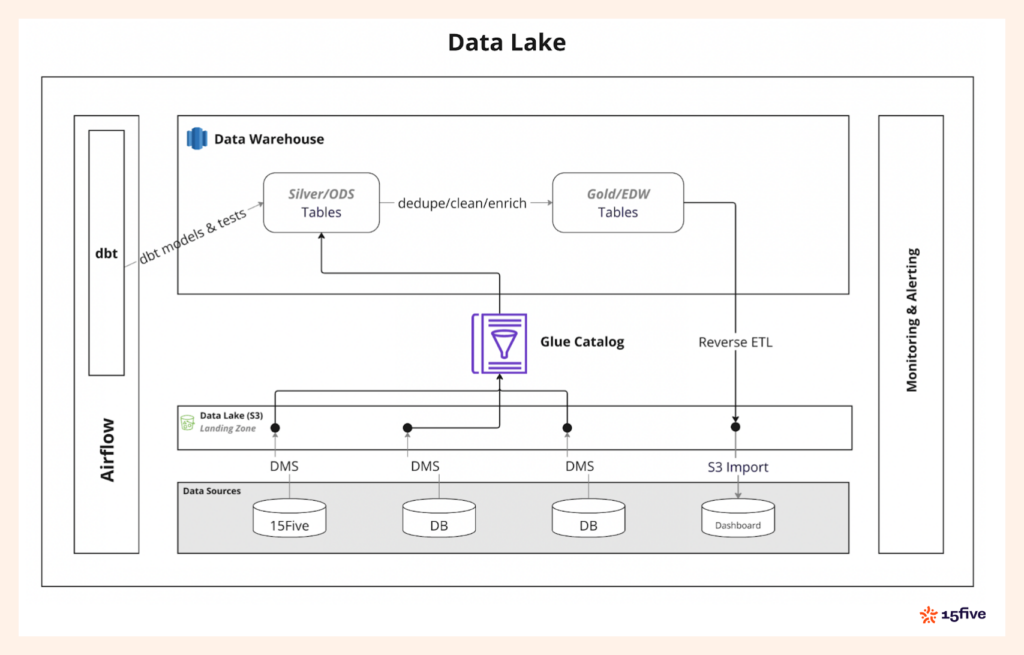
Elegimos una arquitectura del lago de datos para proporcionar flexibilidad y escalabilidad. Amazon S3 sirve como nuestra única fuente de verdad, asegurando que los datos estén centralizados y estén disponibles para analíticos, informes y cargas de trabajo de aprendizaje automático que respaldan las decisiones estratégicas de recursos humanos.
La arquitectura de Information Lake también nos brinda un management completo sobre la cadencia de ingestión de datos para la toma de decisiones ágiles. Esto significa que podemos optimizar cuándo y cómo se procesan los datos, reduciendo los costos, particularmente con nuestro almacén de datos de desplazamiento rojo sin servidor. Alineamos la ingestión de datos con los requisitos comerciales para mantener la eficiencia sin sobreprovisionamiento.
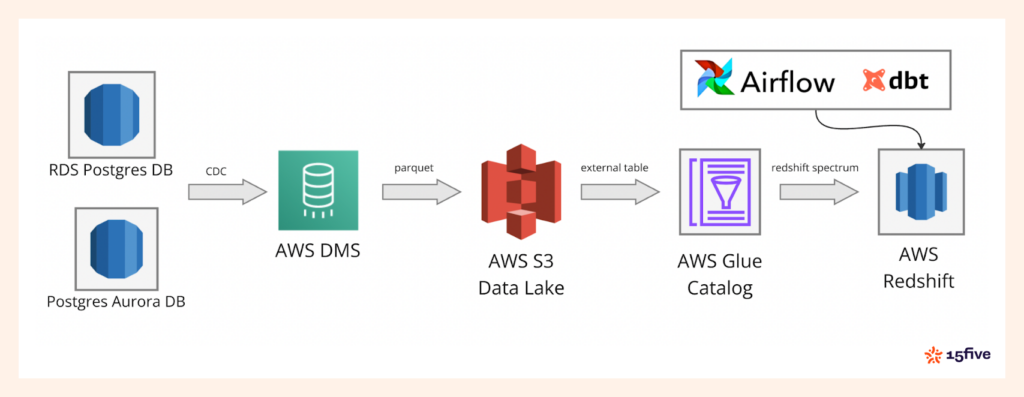
En el diagrama anterior, puede ver la arquitectura completa, comenzando con la ingestión de datos a través de AWS DMS en el lago de datos basado en S3. De eso, Catálogo de pegamento de AWS Administra metadatos, mientras que el espectro de desplazamiento rojo procesa los datos. Todo el flujo de trabajo se orquesta usando Flujo de aire de Apache y DBTgarantizar operaciones y transformaciones de datos suaves.
Ingestión de datos
Nuestra tubería de datos ingiere datos de más de 100 tablas de base de datos transaccionales. Queríamos una solución fácil de mantener y escalable para este proceso, y Servicio de migración de datos de AWS (DMS) Ajusta el proyecto de ley. DMS facilita la replicación de datos sin problemas de nuestras bases de datos transaccionales en el lago Information.
Participamos los datos con granularidad por hora, lo que facilita la consulta y gestiona períodos de tiempo específicos. El Parquet El formato de archivo nos ayuda a optimizar el almacenamiento y la recuperación, asegurando consultas eficientes para el análisis aguas abajo.
Esta arquitectura nos permite manejar grandes volúmenes de datos mientras mantenemos flexibilidad a medida que escala.
Catálogo de datos con pegamento AWS
Para permitir que RedShift consulte los datos almacenados en S3, utilizamos AWS Glue para crear esquemas externos que se asignen a los prefijos S3 que representan nuestras diversas tablas de datos. Una vez que se configuran la base de datos y las tablas de pegamento, tenemos dos opciones:
- Use rastreadores de pegamento para inferir automáticamente el esquema y las particiones.
- Use una función AWS DMS que actualice automáticamente el catálogo de pegamento a medida que llegan los nuevos datos.
Sin embargo, encontramos problemas de confiabilidad con la función DMS: causó bloqueos frecuentes, lo que llevó a espacios de replicación en las bases de datos de origen que se eliminan. Esto causó la pérdida de datos, lo que contradice el objetivo de facilidad de mantenimiento que inicialmente buscamos.
Como solución, desarrollamos un proceso personalizado utilizando AWS SNS y AWS Lambda para actualizar automáticamente el catálogo de pegamento y las particiones cuando los nuevos archivos aterrizan en S3. Esta solución interna ha asegurado metadatos de pegamento en tiempo actual y actualizaciones de partición, proporcionando una alternativa más confiable a las características de DMS.
Transformación de datos con DBT
Para la transformación de datos, confiamos en DBT (herramienta de compilación de datos). Usando DBT, transformamos los datos sin procesar en capas progresivamente más limpias, dedupadas y más refinadas, siguiendo la arquitectura de medallón. Este enfoque asegura que cada capa de datos esté mejor estructurada y más adecuada para el análisis posterior.
El enfoque modular de DBT mantiene transformaciones de datos consistentes y confiables. Nuestro proceso de transformación por etapas garantiza que los datos siempre estén estructurados y optimizados para informar.
Calidad y prueba de datos
Para mantener la integridad de nuestros datos, implementamos pruebas exhaustivas utilizando DBT y excelentes expectativas. Para DBT, definimos las pruebas en propiedades del modelo YAML archivos, validando métricas clave de la calidad de los datos como la unicidad, los valores no nulos y las relaciones entre las tablas. Estas pruebas se ejecutan durante el proceso de transformación, atrapando cualquier problema desde el principio.
También realizamos pruebas unitarias en modelos DBT antes de la implementación, lo que garantiza que ningún problema estructural o lógico impacte la precisión de la salida del modelo y los datos aguas abajo. Para los datos consumidos por los sistemas externos (como en el ETL inverso), seguimos un patrón de escritura, auditoría y publicado para validar los datos.
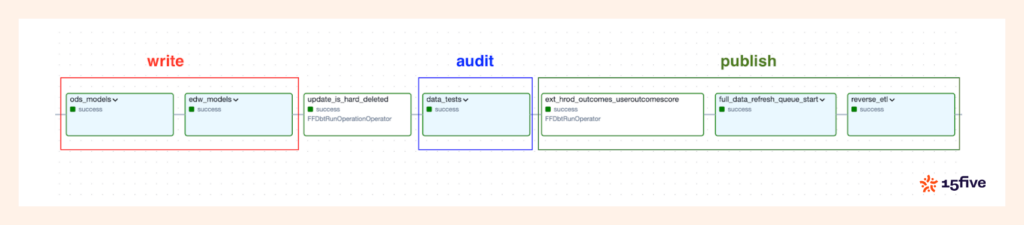
Si alguna prueba falla, se detiene toda la tubería (DAG) y se notifica a nuestro equipo a través de Opsgenie. Esto evita que los datos malos se ingieran en las bases de datos de aplicaciones o lleguen a los clientes.
ETL invertido para datos procesados
Para servir los datos transformados a la aplicación orientada al cliente, revertimos los datos en nuestras bases de datos de aplicaciones. Descargamos los datos del desplazamiento rojo en un cubo S3 utilizando el desplazamiento rojo DESCARGAR consulta. A partir de ahí, usamos PostgreSQL s3_import Característica para importar los datos a la base de datos Postgres que alimenta la interfaz de usuario de la aplicación.
Este proceso de ETL inverso asegura que los datos transformados se devuelvan de manera eficiente a la aplicación, utilizando UPSERTS con Postgres ‘ Insertar con el conflicto Para mantener la consistencia de los datos sin duplicación.
Herramientas adicionales
Toda nuestra infraestructura se aprovisiona utilizando infraestructura como código (IAC) a través de Terraform. Esto nos permite automatizar la implementación y gestión de nuestros entornos, haciendo que el proceso sea repetible y reduciendo el esfuerzo guide.
Utilizamos Apache Airflow para orquestar toda la tubería de datos, desde la transformación de datos con DBT para revertir ETL. Airflow nos permite administrar flujos de trabajo complejos de manera eficiente, asegurando que cada paso del proceso se ejecute correctamente con visibilidad en cualquier problema potencial.
Conclusión
La construcción de una plataforma de datos robusta requiere una cuidadosa consideración de la arquitectura, las herramientas y los flujos de trabajo. Hemos creado una plataforma escalable, versatile y eficiente que beneficia tanto a los equipos internos como a los clientes externos que utilizan tecnologías como AWS DMS, AWS RedShift, DBT, Apache Airflow y otros.
Esta plataforma nos permite manejar grandes volúmenes de datos, garantizar su calidad y ofrecer información oportuna que impulsen las decisiones comerciales.
Estamos contratando
Con 15five, siempre estamos buscando ingenieros talentosos y científicos de datos. Si está interesado en ayudarnos a construir la próxima generación de gestión de datos de tecnología de recursos humanos, solicite nuestros roles abiertos aquí.
Sobre el autor: Ujwal Trivedii es un ingeniero principal de 15Five y lidera el desarrollo de la plataforma de datos de la compañía, lo que permite productos estratégicos de HR y gestión de rendimiento impulsados por la IA. Se enfoca en construir una infraestructura escalable y basada en datos que alimenta la IA y el análisis de 15five para los líderes de recursos humanos.